
Finetuning Large Language Models
PEFT, QLoRA & More
13th Jun
4 mins
BLOG
You probably came across lines like “Memory-efficient Fine-tuning with QLoRA” , and wondered what it meant or how you too could extract the maximum performance from your models for your specific needs.
In this blog, we’ve uncovered and explained cutting-edge techniques from Full Parameter Training to PEFT, LoRA, and QLoRA, exploring each training approach, and when to use them. Read on!
Full Parameter Training
Full parameter training involves updating all the parameters of a neural network during the training process. The precision of these parameters can significantly affect both the performance and efficiency of model training.
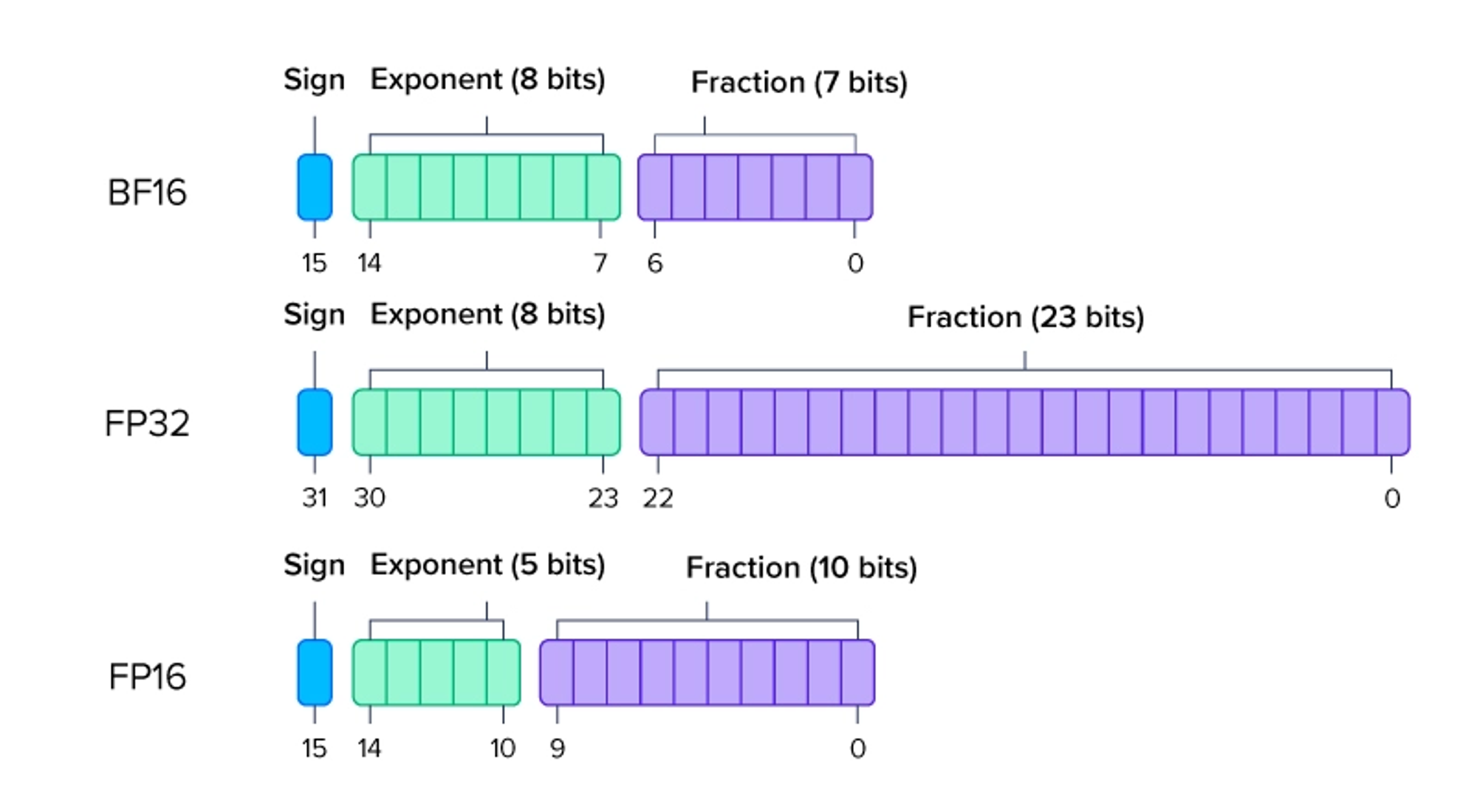
Full Precision (FP32):
Traditionally, models have been trained using 32-bit floating-point precision (FP32). Each model weight in FP32 is represented using 32 bits (4 bytes), providing high numerical accuracy and stability.
Specifically, FP32 can represent decimal numbers with up to 7-8 significant digits of precision, whereas FP16 can only represent numbers with approximately 3-4 significant digits. For instance, a weight of 0.12345678 in FP32 might be represented as 0.1235 in FP16, illustrating the reduced precision.
This high precision and stability, however, comes at the cost of computational resources and energy.
FP16 (Half Precision):
Using 16-bit floating-point precision speeds up training by reducing the memory bandwidth and storage requirements. By halving the number of bits used to store each weight (from 32 bits to 16 bits), the amount of memory required for storing the model parameters is effectively cut in half.
This reduction in memory and storage allows for more data to be loaded into the GPU's memory at once, reducing the need for frequent memory transfers. Additionally, lower memory bandwidth usage leads to faster data processing, thereby speeding up training times. Research has shown that mixed-precision training, which uses both FP16 and FP32, can maintain model accuracy while significantly boosting performance. As per "Mixed Precision Training" by Micikevicius et al.", mixed-precision training should involve using FP16 for most operations while maintaining a master copy of weights in FP32 to ensure stability and accuracy.
When to Use Full Parameter Tuning:
-
Large Datasets: Full parameter tuning is ideal when you have a large diverse and comprehensive dataset, typically consisting of hundreds of thousands to millions of examples.
Why: With a large dataset, the model can effectively learn and generalize from a wide range of inputs, thereby minimizing the risk of overfitting. Updating all the model's weights allows it to capture intricate patterns and nuances leading to improved performance on the training and validation sets.
-
Specific Task Requirements: Full parameter tuning is beneficial when the task requires substantial modifications from what the pre-trained model was originally trained to do.
Why: By updating all parameters, the model can significantly alter its behavior to better suit the specific requirements of the new task.
Example:
BloombergGPT, Bloomberg's 50B parameter LLM, retrained from scratch using specialized financial datasets to handle intricate demands of financial analysis, and generate precise, context-specific output.
Full parameter tuning is resource-intensive, requiring substantial computational and memory resources.
PEFT (Parameter Efficient Fine-tuning)
PEFT, or Parameter-Efficient Fine-tuning, is a technique designed to update a small subset of a pre-trained model's parameters. This approach is advantageous when computational resources are limited or when deploying multiple specialized models from a single general model.
Parameter Efficient Fine-tuning (PEFT) is particularly useful for scenarios where it's crucial to maintain a model's general capabilities across multiple tasks while also adapting it to perform well on a specific task. By training only a small number of task-specific adapter layers and parameters, PEFT helps to preserve the original model's weights, thereby reducing the risk of catastrophic forgetting.
PEFT is also useful in scenarios where fine-tuning needs to be done on edge devices or where storage is a premium. For example, fine-tuning a language model for medical language processing on hospital servers with strict data privacy regulations and limited hardware capacity.
Major types of PEFT techniques:
- Selective: Select subset of initial LLM parameters to fine-tune
- Reparameterization: Reparameterize model weights using a low-rank representation (LoRA)
- Additive: Add trainable layers or parameters to models (Adapters, Soft Prompts or Prompt Tuning )
Please note that prompt tuning is not prompt engineering.
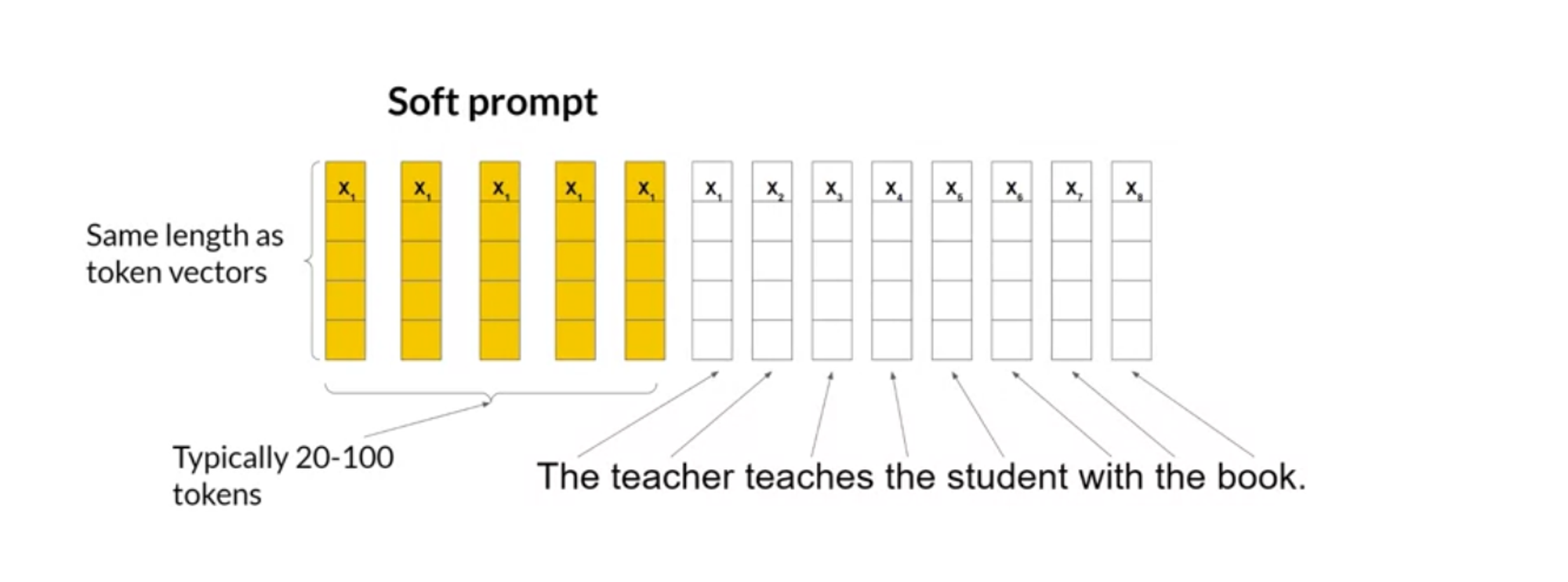
Prompt tuning adds trainable "soft prompt" to inputs
When to Use:
-
Moderate to Small Datasets: PEFT is effective when the dataset size is relatively small or moderate (e.g., a few thousand to tens of thousands of examples). It avoids overfitting by limiting the number of parameters that get updated.
-
Preserving General Capabilities: This method is ideal if the task requires the model to retain its performance across a variety of tasks, not just the one it's being fine-tuned for, thereby minimizing catastrophic forgetting.
Example: Fine-tuning a model for a specific legal document analysis task where it's crucial to maintain the model's general language understanding abilities.
LoRA and QLoRA
LoRA (Low-Rank Adaptation) and QLoRA (Quantized Low-Rank Adaptation) is a sub category of PEFT and are techniques that modify a small number of additional parameters instead of the original model weights during adaptation.
-
LoRA: This method introduces low-rank matrices that are applied to the weights of each layer, effectively allowing the model to adapt to new tasks with minimal updates. "LoRA: Low-Rank Adaptation of Large Language Models" by Hu et al. Is a foundational paper that demonstrates the efficacy of this method (https://arxiv.org/abs/2106.09685).
-
QLoRA: An extension of LoRA, QLoRA uses quantized values for the low-rank matrices, further reducing the memory footprint and computational demands. Quantization refers to the process of converting continuous values into discrete ones, typically by reducing the number of bits used to represent each value. QLoRA is relatively new and research is ongoing to establish its effectiveness and best practices.
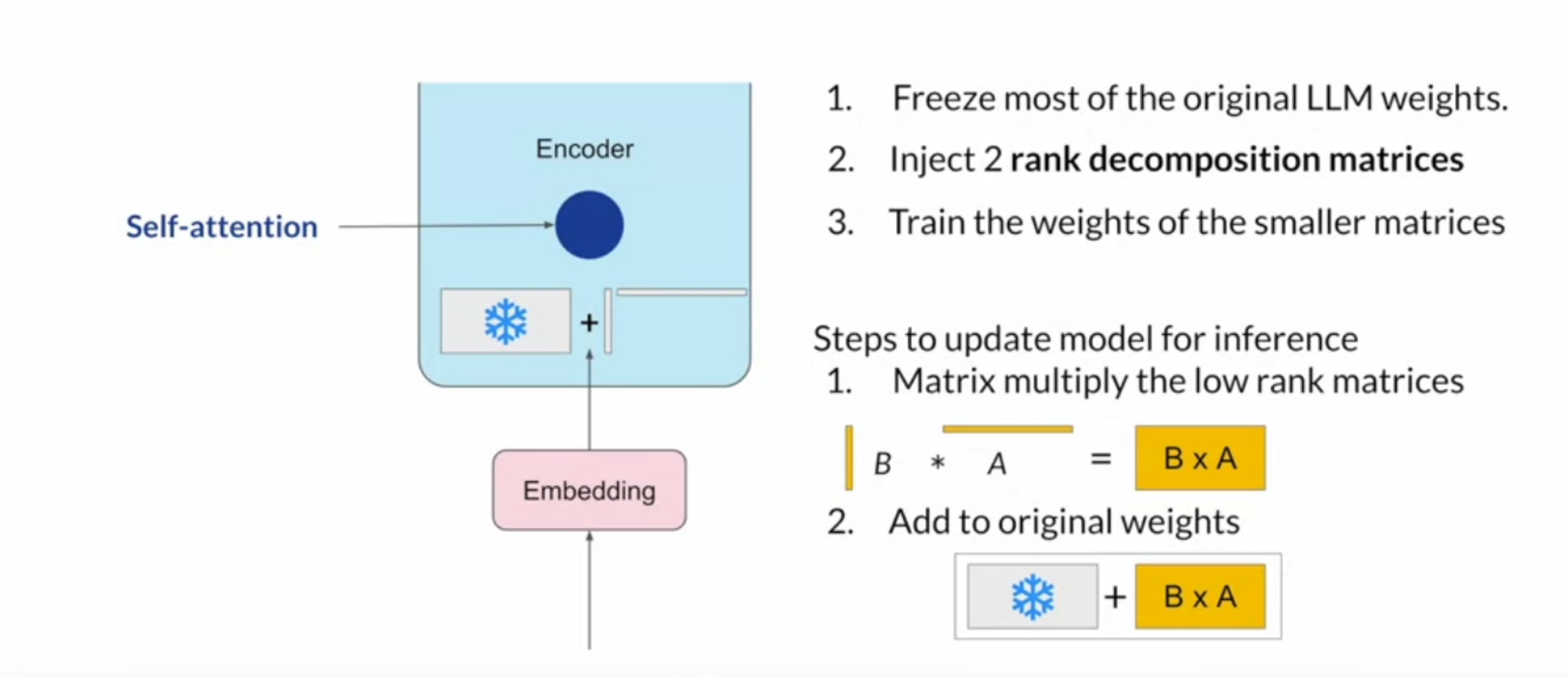
LoRA -> use the base mode weights along with low rank matrices trained for specific tasks
For example: using a base transformer model presented by Vaswani et al. 2017:
- Transformer weights have dimensions d x k = 512 x 64
- So total trainable parameters = 32,768
In LoRA with rank r = 8:
- A has dimensions r x k = 8 x 64 = 512 parameters
- B has dimensions d xr = 512 x 8 = 4096 trainable parameters
- 86% reduction in parameters to train!
When to Use:
-
Very Small to Moderate Datasets: LoRA is particularly useful for datasets ranging from a few hundred to several thousand examples. It introduces adaptability through low-rank matrices that adjust the model's behavior without the need for large-scale weight modifications.
-
Resource Constraints: Since LoRA focuses on adapting a small number of additional parameters, it's less computationally intensive than full parameter tuning, making it suitable for environments with limited hardware capabilities.
-
Fine-tuning with Minimal Disruption: LoRA allows the model to adapt to new tasks or domains while keeping most of the original pre-trained parameters intact, thus preserving the model's broader capabilities.
Example: Adapting a pre-trained model for a targeted sentiment analysis task in a specific industry like automotive or pharmaceuticals, where only slight modifications are needed relative to the base capabilities of the model.
Conclusion
Choosing the right training technique for a large language model depends on several factors including the available computational resources, the desired accuracy, and the specific application requirements. Full parameter training offers the highest accuracy but at a high computational cost. Techniques like PEFT and LoRA provide more efficient alternatives by reducing the number of parameters that need to be updated, while INT8 and INT4 quantization allow for training on resource-constrained devices. Each of these methods has its place in the toolkit of machine learning engineers, and ongoing research continues to refine and expand their applicability and effectiveness.
© 2026 Emissary. All rights reserved.