
Finetuning our way to a better Evaluator LLM
1st Jun
4 min
BLOG
tl;dr: A finetuned open-source model can outperform prompting GPT-4o with <2000 samples for <$20 in ~12 hours on complex tasks like evaluation.
Overview
With the growing adoption of prompted Large Language Models (LLMs) across enterprises, a core question that has emerged is - is finetuning still relevant? And if so, what are the heuristics defining use-cases where finetuning could be beneficial - questions like 'how many samples do we need?' 'How much will it cost?' and most commonly, 'how do I start finetuning' pop up regularly.
Parallely, evaluating generative outputs from LLMs has emerged as a core challenge. Given the lack of deterministic ideal outputs, traditional statistical methods are no longer sufficient, and subjective evaluations have come to the forefront. In order to scale such evaluations, using LLMs as judges of their own output is now common practice.
So, at Emissary, we decided to tackle two birds with one stone - and documented our journey to finetuning a evaluator LLM that outperforms cutting-edge prompted LLMs on the Emissary platform, tracking core heuristics like cost, dataset sizes and time, to help companies ascertain if finetuning might be the pathway for them. Below, we'll walk you through the three core pillars of every finetune - dataset preparation, backbone selection and training approach selection in detail.
Dataset Preparation
The first key requirement of every finetune is preparing a dataset of inputs and outputs. On the Emissary platform, we standardize this to a csv file consisting of two columns - 'input' and 'expected output', much like conventional machine learning experiments.
For our needs, we started by converting an open-source dataset, HelpSteer - consisting human annotated of a training set of 176665 entries and the validation set of 8945 entries - to our desired csv format. Each sample in this dataset comprises human evaluations of a query and its response scored between 0-4 along 5 dimensions - Helpfulness, Correctness, Coherence, Complexity, Verbosity - which happen to be the most commonly used metrics. In our case, we select 20000 training samples and the input is formatted as follows:
1### Instruction: 2You are an LLM evaluator and your task is to evaluate the response for a user input based on the given metric. The result should contain only the score defined within the scale definition 3 4### Input: 5{row['query']} 6 7### Response: 8{row['response']} 9 10### MetricName: 11{row['metric_name']} 12 13### MetricDescription: 14{row['metric_description']} 15 16### ScaleDescription: 17{scale_descriptions2[row['metric_name']]} 18 19### EvaluationScore:
And output as
1_score_
and each line of our csv is then simply the input, output
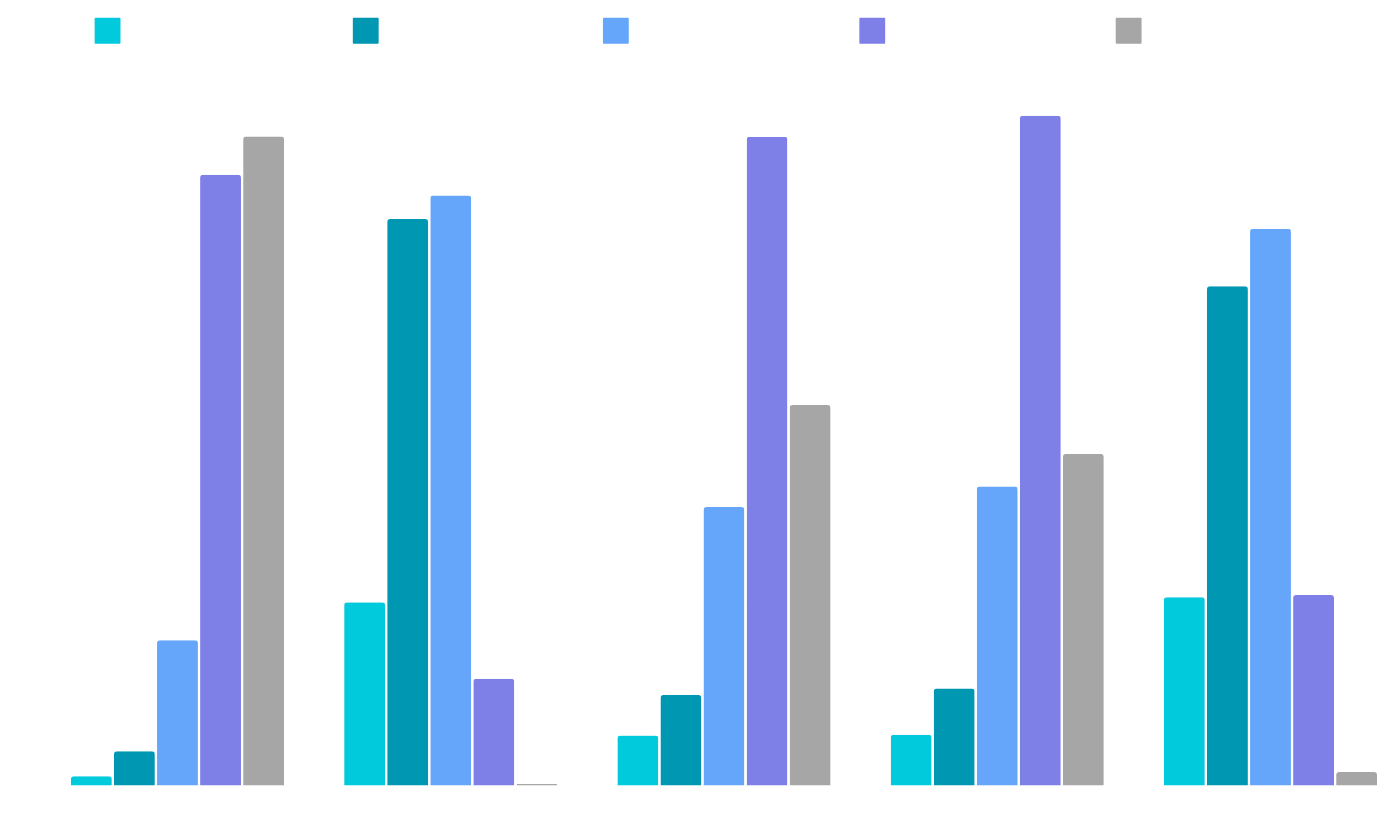
1/5 of the samples correspond to each of metric and the score distribution is as below:
Backbone Selection
Every finetune requires the selection of a pretrained backbone. A backbone is simply a base model that has been trained on some standard, openly accessible dataset.
In our case, we choose to finetune multiple different models to compare performance across them. We choose 3 popular pretrained models - Mistral, Llama 2 and Falcon, all 7B parameter versions.
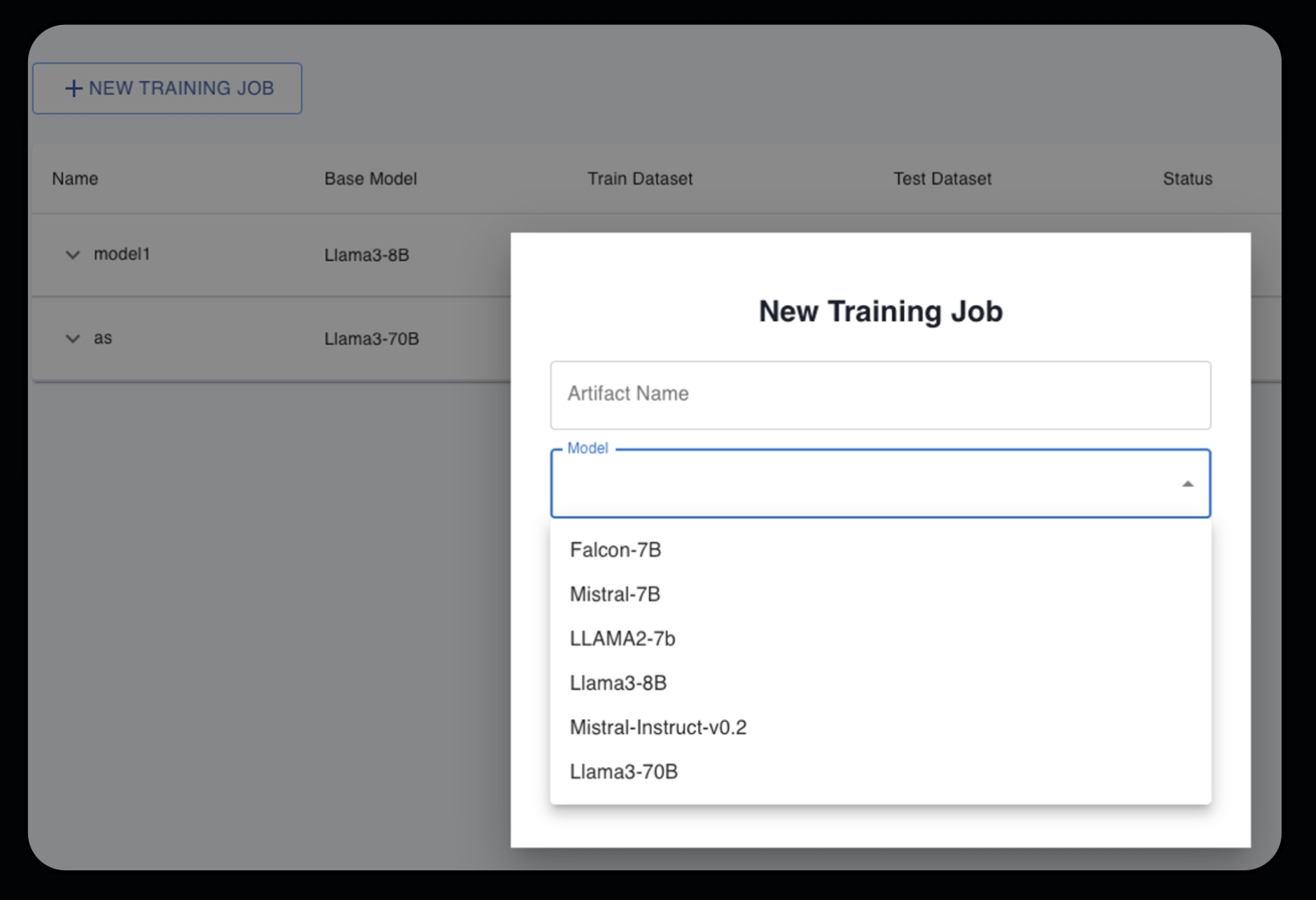
On Emissary, finetuning different backbones simply requires kickstarting different training jobs in parallel with the requisite model selections from the drop-down selector.
Training Technique
The third core choice to make is the training approach. There are two main options:
- PEFT (Parameter Efficient Finetuning) with QLORA (Quantized Low-Rank Adaptation): This approach updates a small, low-rank subset of model parameters and uses quantization to reduce memory usage, enabling effective fine-tuning on resource-constrained devices without sacrificing performance. Basically, allow only a few key parameters/weights of the model to get updated during training while freezing most.
- Full parameter training with half precision: Allow all parameters of the model to get updated during the training process. In our case, we use half precision (16 bit floating point) to reduce memory requirements.
On Emissary, there is a single field under 'Advanced Training Options' within the training jobs modal that allows you to flip between these two settings.
For the purposes of evaluation, we train across both.
The Training Process
The training process involves using a training script that codifies the training technique - that is, how the weights of the chosen backbone model, across the training dataset. Here, we also define a few hyperparameters that are simply additional knobs we can tweak to further optimize the way weights are updated. Our configurations are as follows:
Fine Tuning using PEFT with Quantization
- Key Parameters:
- Epochs: 2
- Batch Size: 4
- optimizer: paged_adamw_32bit
- learning rate: 0.0002
- max sequence length: 2048
- LORA Configurations: Alpha: 32; Rank: 32 and 64
- Training time per job: 5-7 hrs.
- Fine Tuning Cost: ~$6 per training job
- Hardware used: 1 NVIDIA A10 GPU with 24 GB of VRAM. (g5.xlarge on AWS, $1.006/hr)
Full Parameter Fine Tuning with BF16 Precision
- Key parameters:
- Epochs: 2
- Batch Size: 8
- optimizer: paged_adamw_32bit
- learning rate: 0.0002
- max sequence length: 2048
- Training Time: 8-10 hrs.
- Fine Tuning Cost: ~$50 per training job
- Hardware Used: 4xA10 GPUs = 96 GB VRAM (g5.12xlarge on AWS, $5.672/hr)
Don't want to deal with these complexities? On the Emissary platform, we have pre-defined training scripts for all these models that ensure you can simply bring a dataset and hit the ground running. We even recommend optimal parameters and automatically route your training job to the optimal GPU instances, ensuring that you can focus on outcomes, instead of getting bogged down in the mechanics of finetuning.
Baselines
In order to validate our system's performance, we use a test set from the same HelpSteer dataset and compare its results to SoA closed source models - GPT4 and GPT4-o. We also compare the finetuned models to Prometheus - a separate opensource LLM finetuned for evaluation on GPT4-generated data.
Results
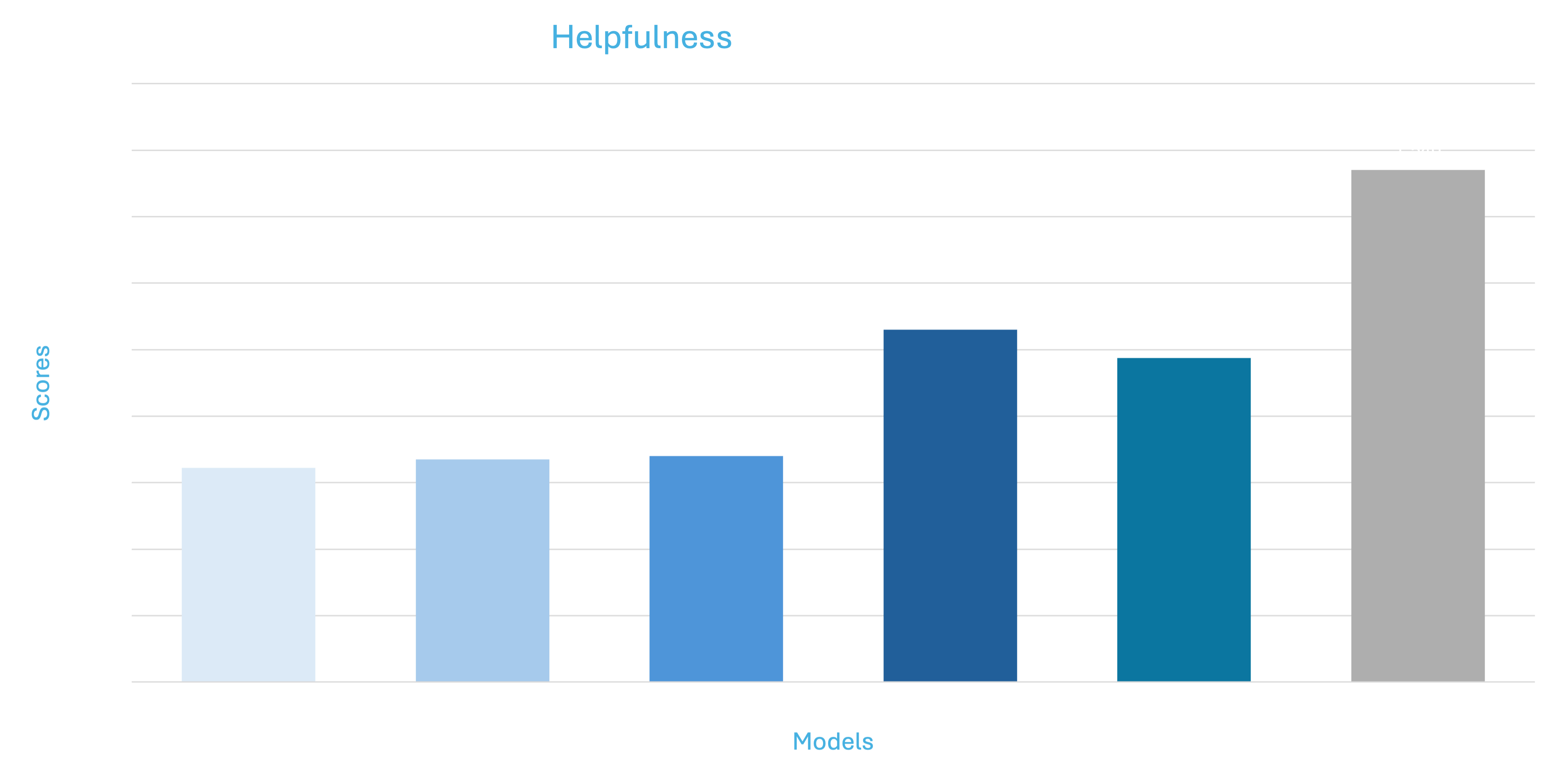
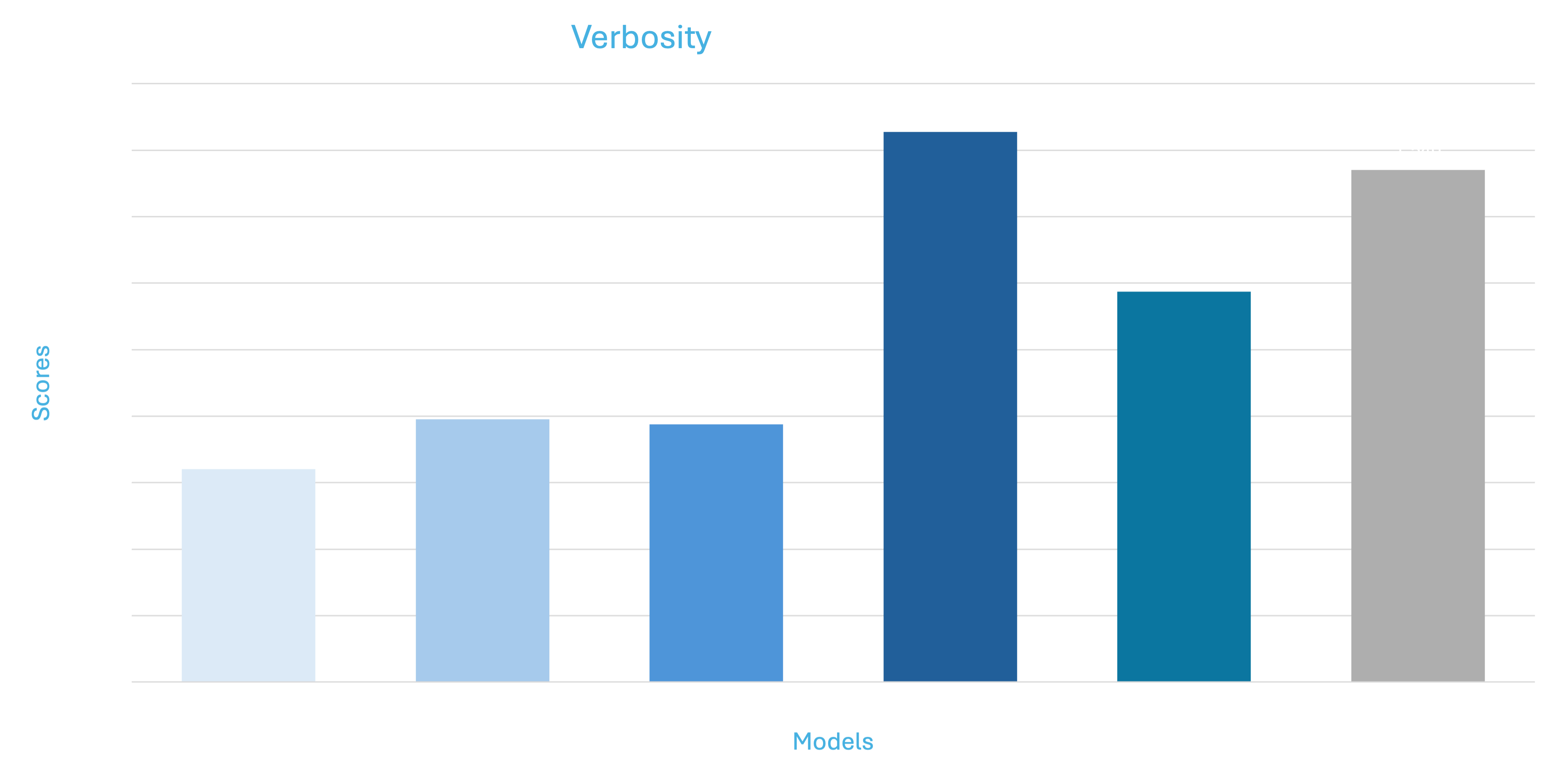
The results can be viewed in the various visualizations reflecting the delta differences between the expected outcome and performance of the model.
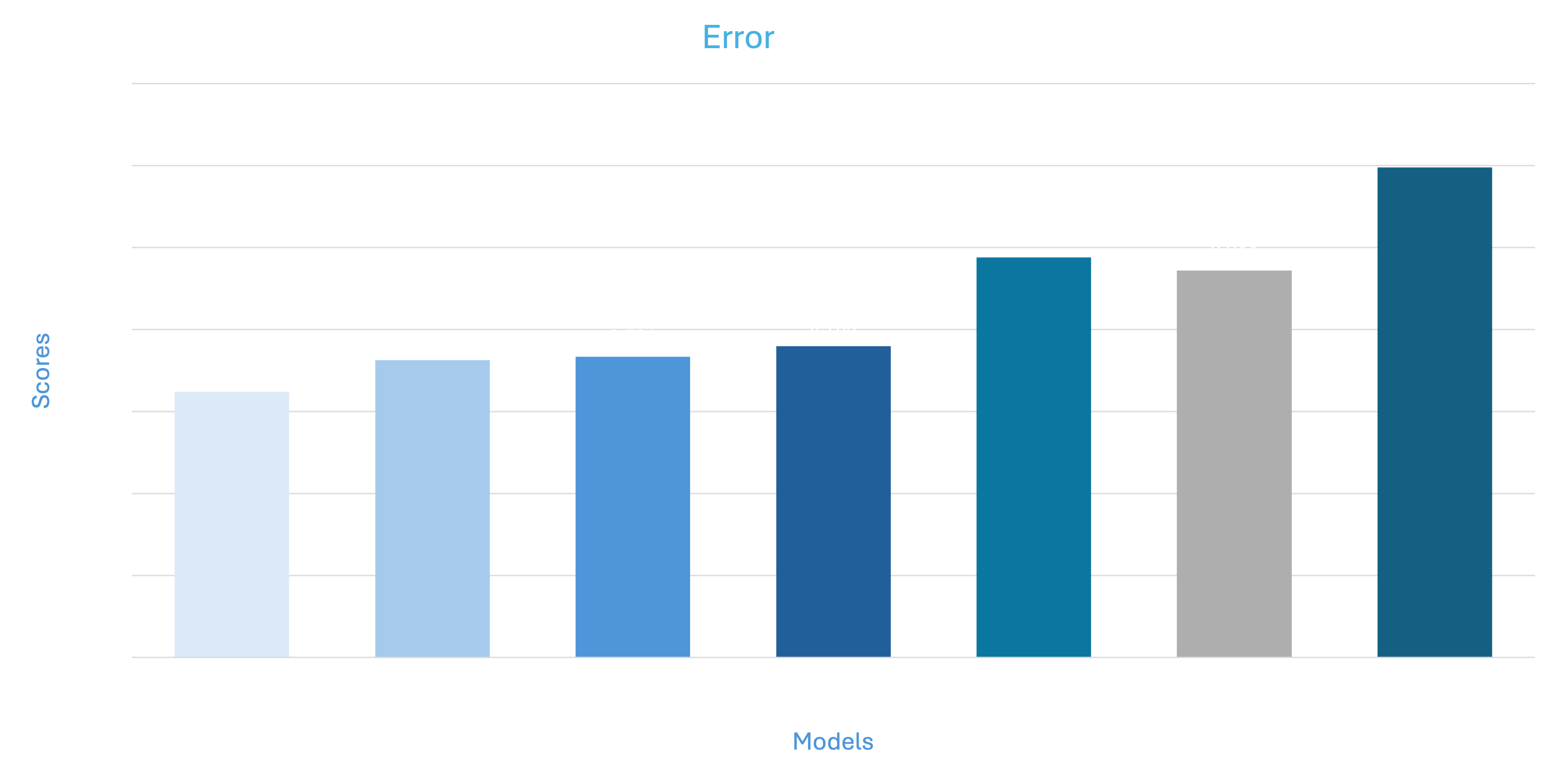
The scores in the above graphs depict the mean deviation from the actual score
- Finetuned models significantly outperform GPT models on evaluation tasks.
- The Mistral-7B is the best performing model, although there is very marginal difference across the backbones.
- Parameter-efficient tuning outperforms full-parameter finetuning on our relatively small sample set.
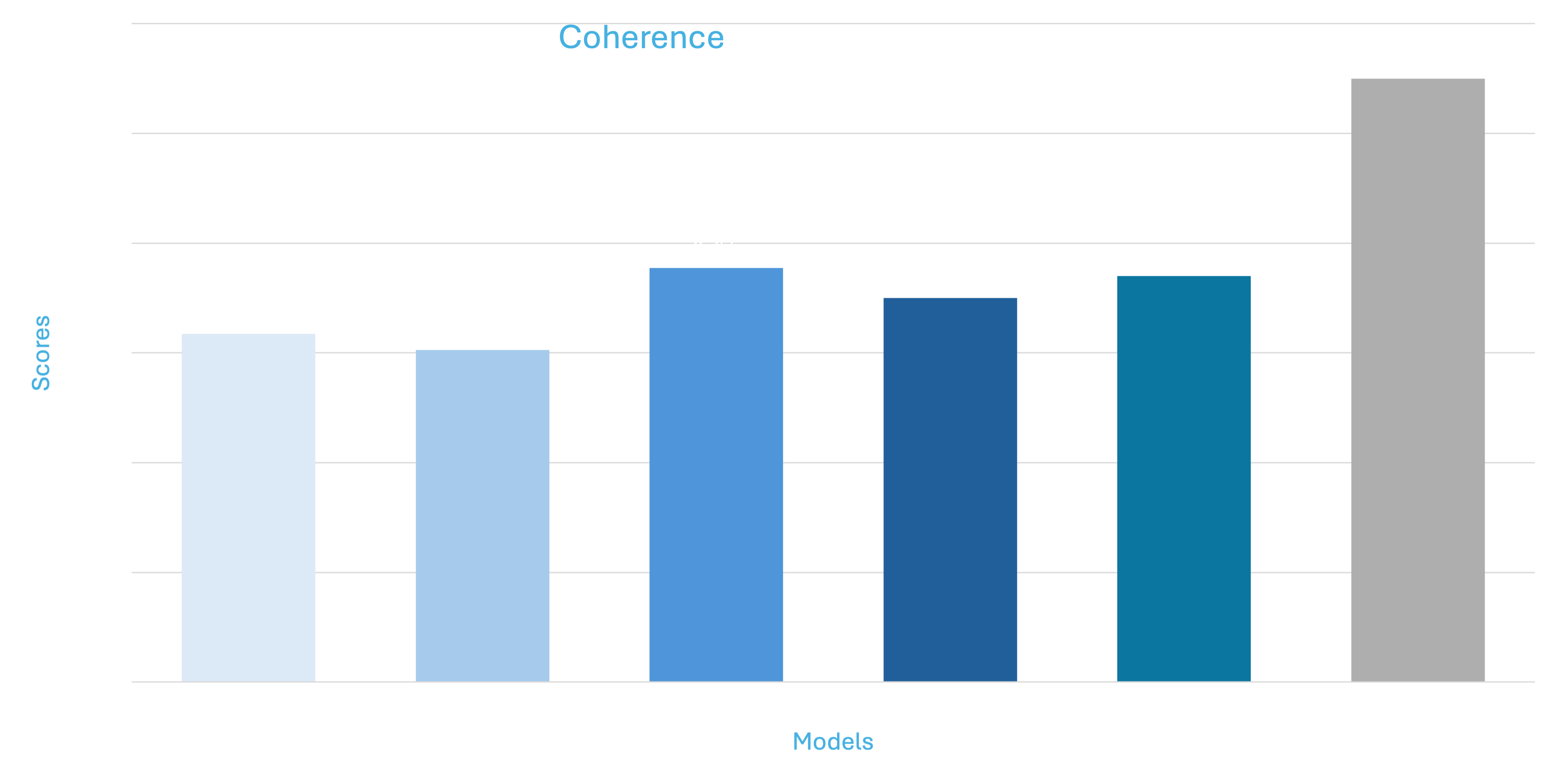
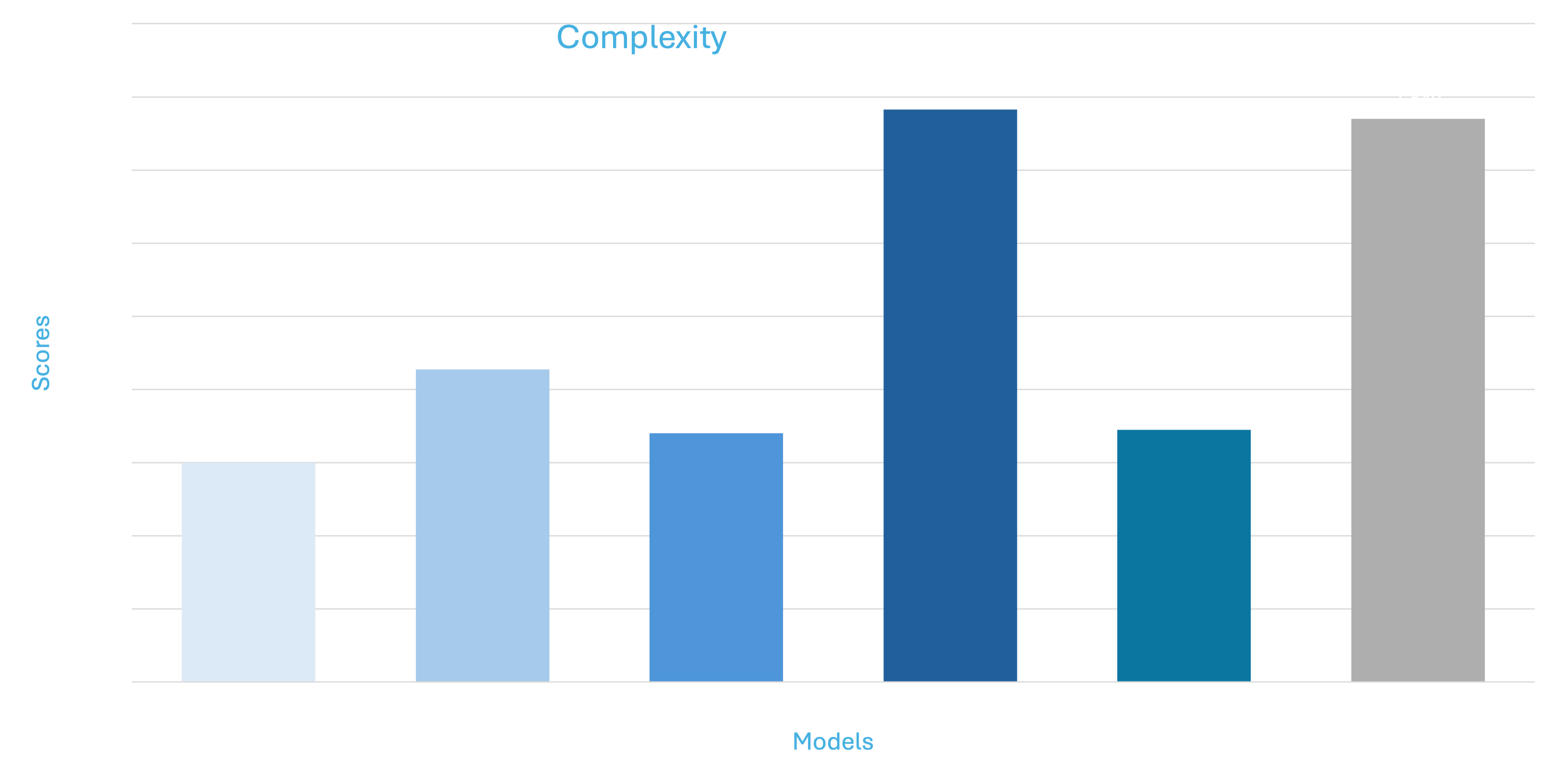
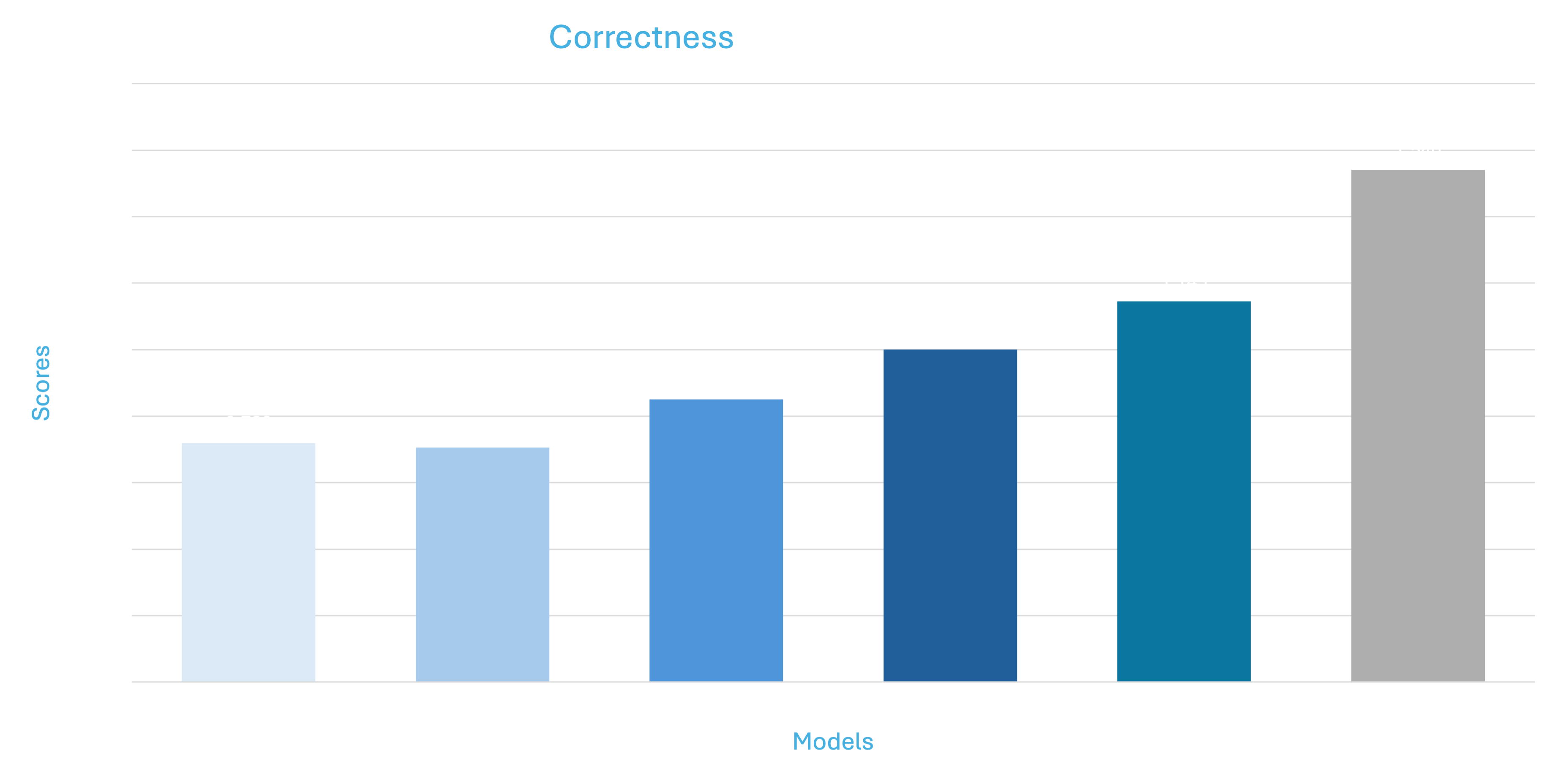
The above graphs show mean deviation for individual metrics
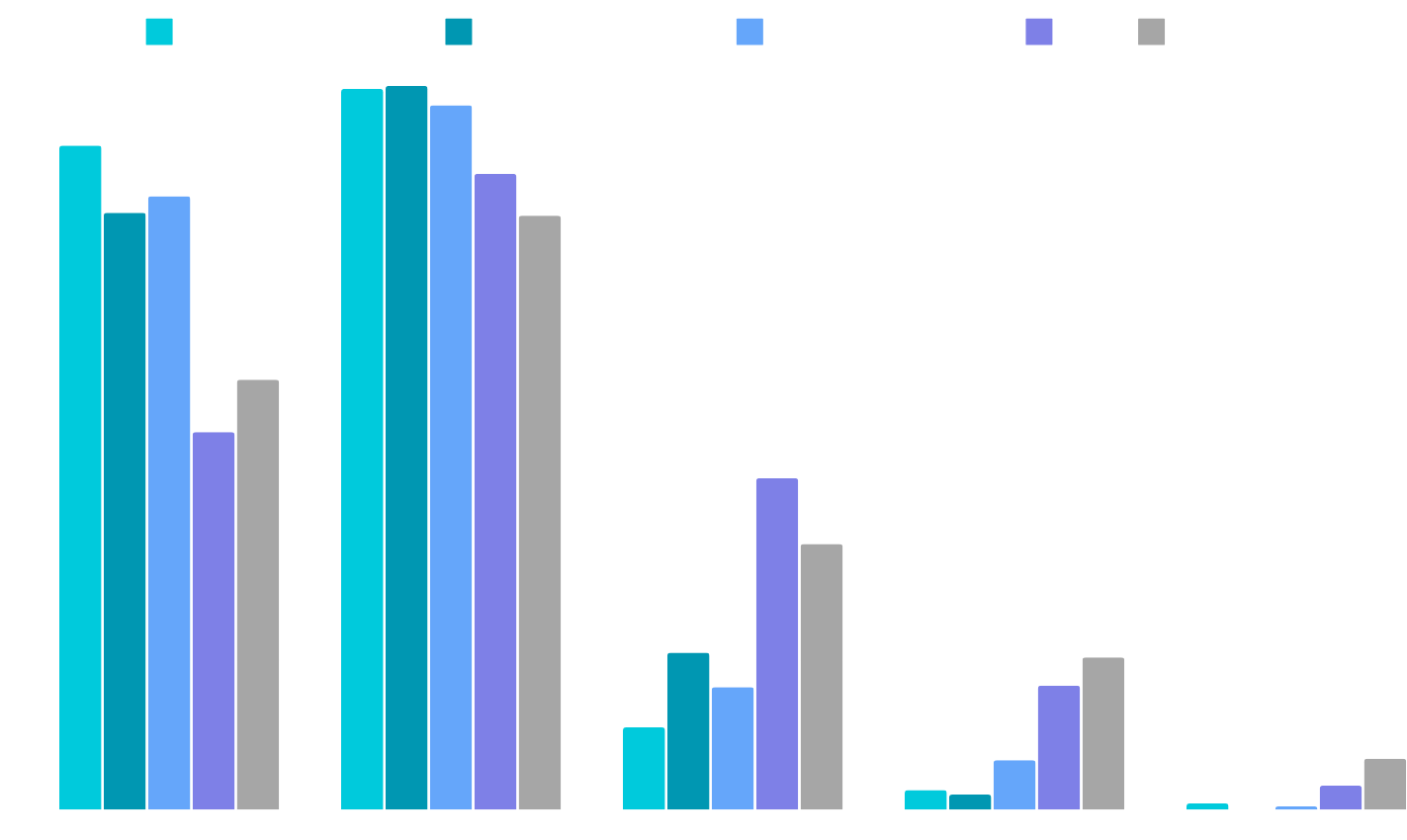
*Please note that all the models (Falcon, Mistral, Llama) are trained using 4 bit quantization and QLORA
Conclusion:
Fine-Tuning Yields Superior Performance, regardless of backbone choice.
Our recent experiments demonstrate that fine-tuning smaller LLMs on even modestly-sized datasets can significantly outperform larger, state-of-the-art models like OpenAI's GPT-4o in specific tasks, even when complex. As illustrated in the "Mean Deviation Comparison" graph, fine-tuned models on datasets as small as 1,000 samples show promising results, with a mean deviation score of 0.802. This score steadily improves as the sample size increases, showcasing enhanced performance with additional data. However, even at 18,000 samples, these fine-tuned models achieve a mean deviation of 0.621, which is considerably lower than GPT-4’s score of 0.944.
These findings suggest a compelling advantage of fine-tuning: it allows smaller models to specialize and adapt to specific tasks more effectively than larger, generalized models. This capability not only makes fine-tuning a valuable strategy for optimizing performance but also highlights its potential in reducing computational costs and improving efficiency. By strategically fine-tuning LLMs on targeted datasets, organizations can achieve superior results that are tailored to their specific needs, surpassing the performance of much larger models that may not be as finely adapted to the task at hand.
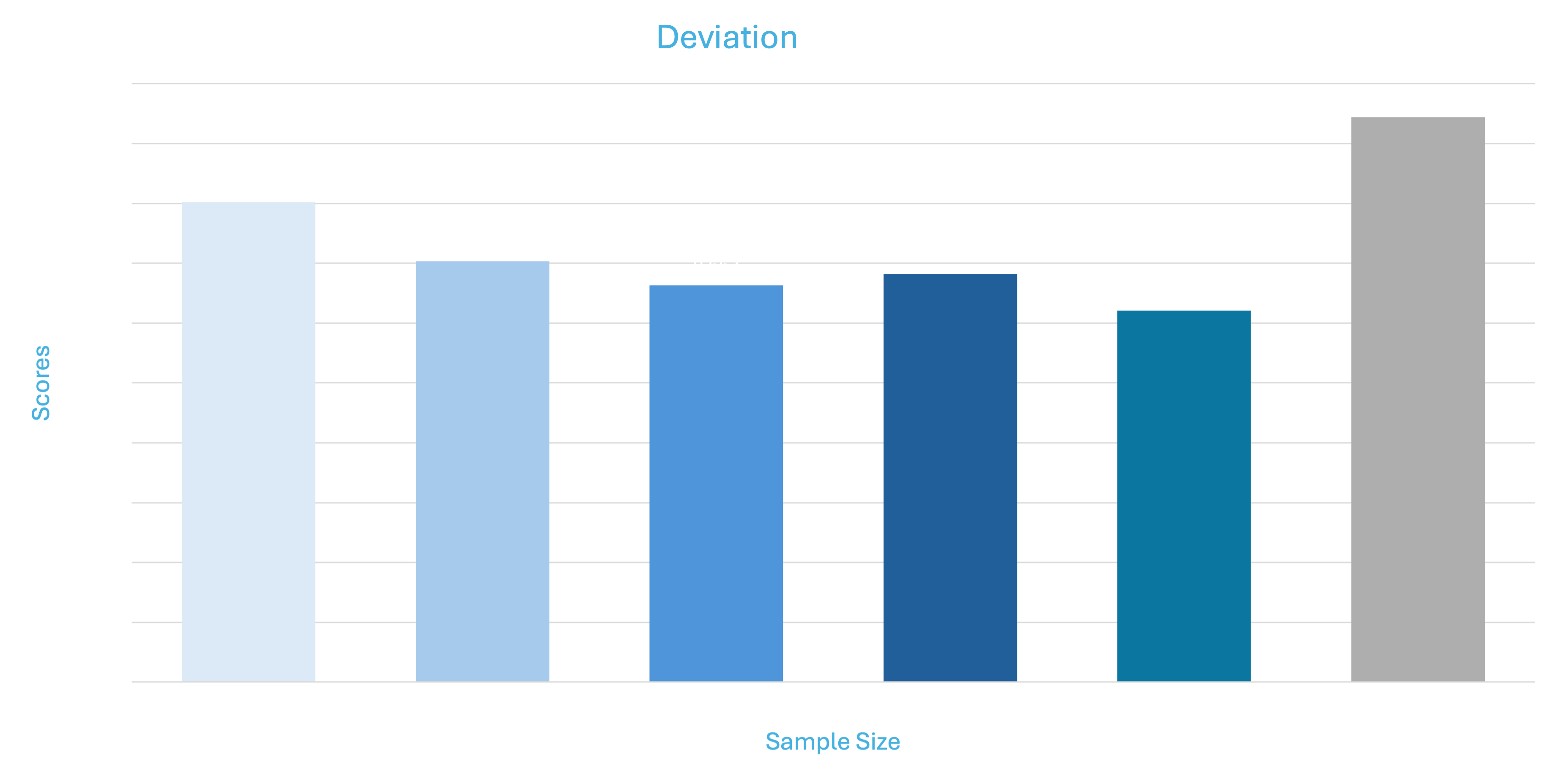
** All the trainings are performed with a total of 3 epochs on the Mistral 7B model (PEFT + QLORA)
Key Takeaways
Our findings suggest that with as few as a thousand samples, finetuning can be a potent weapon for AI teams to outperform prompting, allowing for development of stable and state-of-the-art AI capabilities. Finetuning is incredibly affordable and quick and has high ROI.
Furthermore, given the relatively small deltas across base models, the emphasis should be on curating data and continuous retraining instead of model chasing.
Appendix
© 2026 Emissary. All rights reserved.